MoTIF Spotlight Paper Brings Concept Bottleneck Models to Video Understanding
How can a model explain not only what it sees in a video, but also when important concepts appear, recur, and shape the final prediction?
This question motivates MoTIF, the Moving Temporal Interpretable Framework introduced in the paper “Concepts in Motion: Temporal Concept Bottleneck Model for Interpretable Video Classification” by Patrick Knab, Sascha Marton, Philipp Johannes Schubert, Drago Andres Guggiana Nilo, and Christian Bartelt. The paper has been accepted as a spotlight contribution at the 2nd Workshop on Compositional Learning: Safety, Interpretability, and Agents at ICML 2026.
The workshop focuses on the theoretical foundations of compositionality, its central role in the age of foundation models and agents, and its importance for achieving robustness and systematic out-of-domain generalization. ICML 2026 will take place in Seoul, South Korea, in July 2026.
Concept Bottleneck Models (CBMs) enable interpretable image classification by structuring predictions around human-understandable concepts. Extending this idea to video, however, is challenging: videos require models to reason not only about which concepts are present, but also about how they unfold and interact over time.
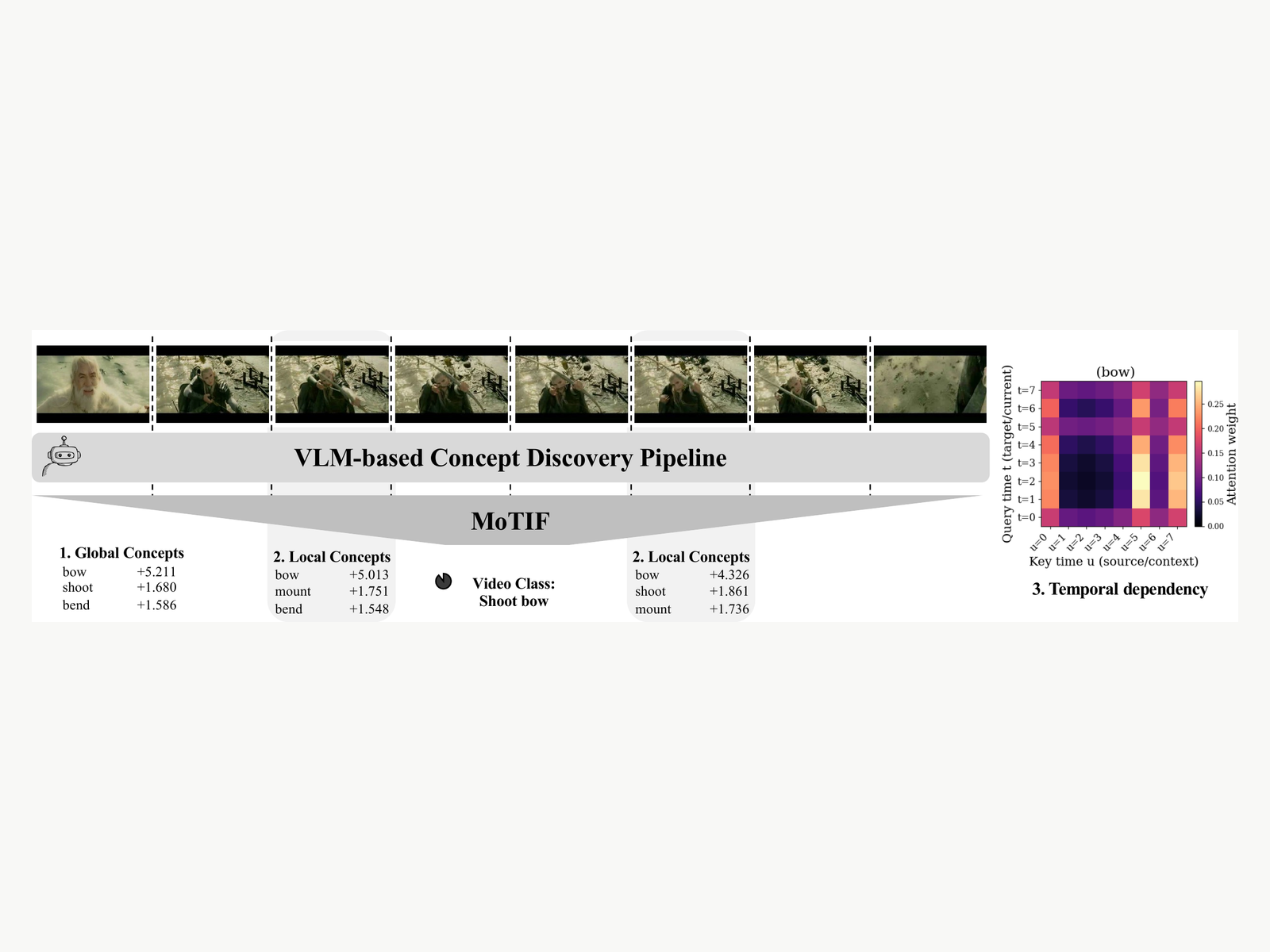
To address this challenge, the paper introduces MoTIF, a transformer-based concept architecture for interpretable video classification. MoTIF operates on sequences of temporally grounded concept activations and uses per-concept temporal self-attention to model when individual concepts recur and how their temporal patterns contribute to predictions. This allows the model to provide multiple perspectives on its reasoning, including global concept importance across a video, local relevance within specific time windows, and temporal dependencies of individual concepts. (arXiv)
A central component of the framework is a class-conditioned VLM-based concept discovery module, which extracts object- and action-centric textual concepts from training videos. This produces temporally expressive concept sets without requiring manual concept annotation. Across multiple video benchmarks, this combination improves over global concept bottlenecks and remains competitive within the interpretable concept-bottleneck setting, while narrowing the gap to strong black-box video baselines used as contextual references.
The full paper can be read here.